Task: Given a speech recording, classify it as real (bonafide) or fake (synthetic) under unknown media transformations.
![]()
Robust Audio Deepfake Recognition under Media Transformations
The RADAR Challenge 2026 is an APSIPA Grand Challenge on robust audio deepfake detection under realistic media conditions. Participants must determine whether a speech recording is bonafide (real) or spoofed (synthetic) after it has undergone unknown media transformations such as codec compression, resampling, background noise, music mixing, and room effects.
While recent advances in speech synthesis and voice conversion have made synthetic speech increasingly realistic, most existing detection benchmarks evaluate systems using clean audio. In practice, however, audio shared through social media, messaging platforms, and online media rarely remains pristine. Instead, it is typically edited, compressed, resampled, or mixed with other sounds before reaching detection systems.
The RADAR Challenge addresses this gap by evaluating detection models under realistic media processing pipelines. By introducing diverse and partially unseen transformations, the challenge emphasizes robustness and generalization, which are critical for real-world deployment.
RADAR aims to establish a benchmark for media-robust audio deepfake detection and encourage the development of detection systems that remain reliable beyond controlled laboratory conditions.
Venue
RADAR Challenge 2026 is organized as an APSIPA Grand Challenge and will be presented at APSIPA ASC 2026 in Bangkok, Thailand.
Quick Updates
- …
- 2026-06-20 The APSIPA ASC 2026 has been moved to Bangkok, Thailand. The paper submission deadline has been extended to 30 June.
- 2026-05-16 The competition has concluded following the paper submission deadline. Preliminary results and Challenge Papers are available on this page.
- 2026-04-23 Phase 2 has started! The evaluation dataset has been sent to eligible teams, and the Submission Portal is now open.
- 2026-04-20 The release of the RADAR2026-eval set has been postponed by two days to April 22, 2026.
- 2026-04-14 The labels for the RADAR2026-dev set have been sent to all participants. The baseline system has been updated with evaluation and analysis scripts to support your paper writing.
- 2026-04-12 Phase 1 has ended with 25 teams advanced to Phase 2. Confirmation emails have been sent to eligible teams. Registration is now closed.
- 2026-04-05 Update to Phase 2 requirements: To be eligible for Phase 2, teams must have at least one Phase 1 submission with an EER below 37%. The registration deadline has been updated to April 10.
- 2026-04-03 The Phase 1 (Development) is in progress, if you haven’t been approved to codabench, contact us asap. You may want to check the Q&A section as well.
- 2026-03-31 Submission Portal is open for Phase 1. The timeline for Phase 2 and paper submission has been changed/extended.
- 2026-03-26 The Evaluation data will include speech in English, Mandarin, Japanese, and Vietnamese.
- 2026-03-25 Phase 1 started! Development data has been sent to registered participants via email. If you didn’t receive it or registered after this day, please contact organizers via email or Github Discussion.
- 2026-03-17 Registration form is ready
- 2026-03-16 Landing Page is UP! 🎉
Competition Results
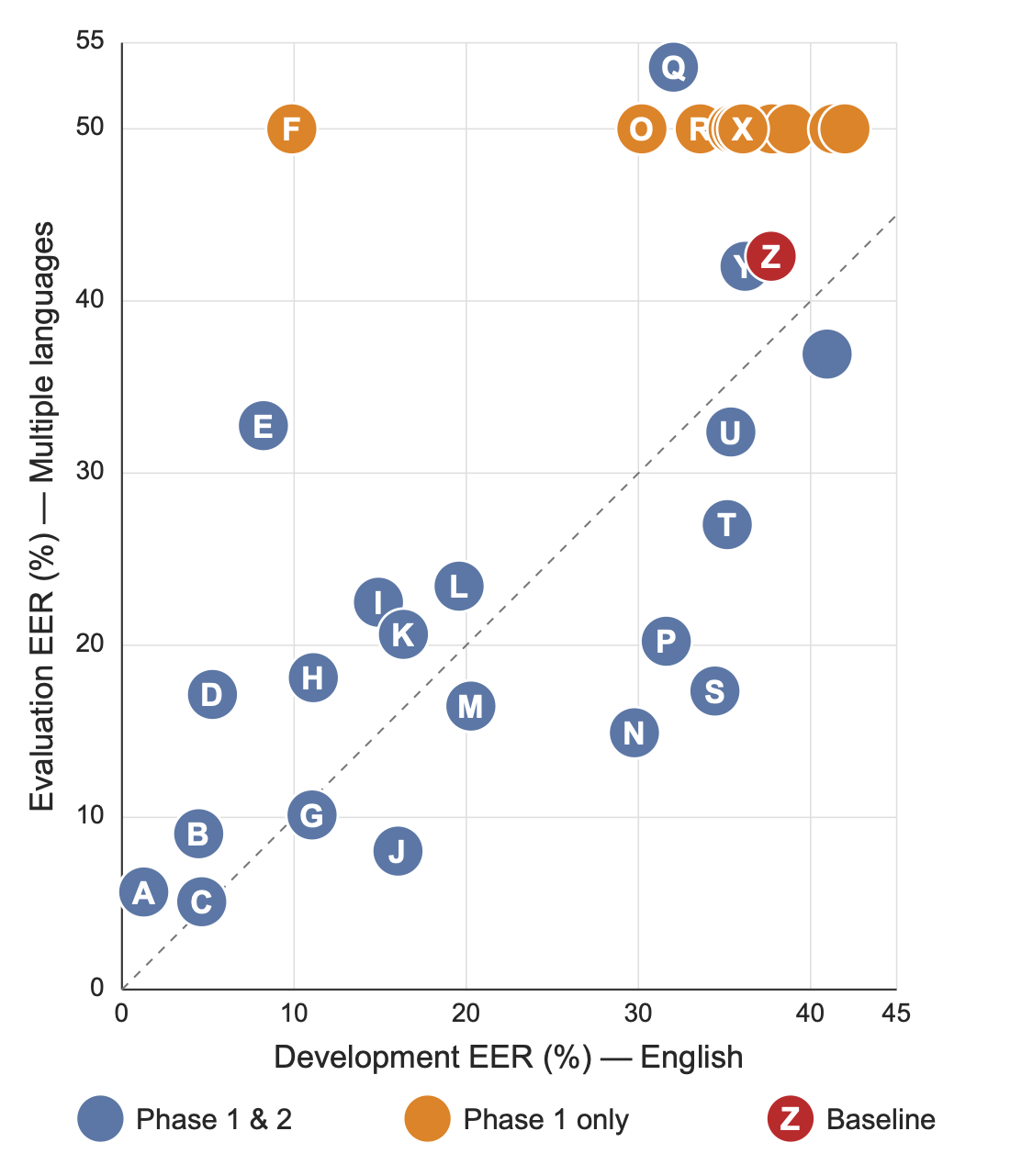
Blue: Phase 1 & 2 participants; orange: Phase 1 only; red: baseline (Z)
These are preliminary results. Official results will be announced at APSIPA ASC 2026 in Bangkok, Thailand.
| Team ID | Dev EER% | Eval EER% | Team ID | Dev EER% | Eval EER% | Team ID | Dev EER% | Eval EER% |
|---|---|---|---|---|---|---|---|---|
| A | 1.27 | 5.67 | N | 29.77 | 14.92 | 27 | 37.75 | — |
| B | 4.46 | 9.05 | O | 30.20 | — | 28 | 38.82 | — |
| C | 4.63 | 5.10 | P | 31.62 | 20.23 | 29 | 40.96 | 36.92 |
| D | 5.26 | 17.14 | Q | 32.03 | 53.58 | 30 | 41.36 | — |
| E | 8.22 | 32.76 | R | 33.59 | — | 31 | 41.99 | — |
| F | 9.87 | — | S | 34.44 | 17.34 | 32 | 47.37 | — |
| G | 11.04 | 10.14 | T | 35.16 | 27.01 | 33 | 71.72 | — |
| H | 11.12 | 18.12 | U | 35.37 | 32.39 | |||
| I | 14.90 | 22.50 | V | 35.50 | — | |||
| J | 16.03 | 8.04 | W | 35.81 | — | |||
| K | 16.35 | 20.63 | X | 36.07 | — | |||
| L | 19.58 | 23.43 | Y | 36.19 | 42.02 | |||
| M | 20.27 | 16.47 | Z (baseline) | 37.71 | 42.60 |
Highlighted cells are the five lowest Eval EER% values among teams with an evaluation score (lower is better). Values match the Codabench leaderboard format.
Challenge Papers
Paper Submission
Teams that had access to the RADAR2026 development set and its labels could submit a system description to APSIPA 2026. The baseline system includes evaluation and analysis scripts for reproducibility and for drafting challenge papers.
- Paper Submission (APSIPA 2026)
Paper submission deadline: June 30, 2026.
When submitting, authors selected the “Grand Challenge: RADAR - Robust Audio Deepfake Recognition under Media Transformations” track, which places more emphasis on technical correctness than on novelty.
Competition Portal
We use Codabench for submissions and the leaderboard:
Please register on Codabench as early as possible, as there is a daily limit on the number of submissions.
Note that the submission deadlines and daily submission limits reset according to UTC time.
Only one member per team will be approved on Codabench.
Registration (Closed)
Please register your team using the registration form:
Register for RADAR Challenge 2026(Registration Closed)
Registration deadline: April 10, 2026. By registering, you agree to the Terms & Conditions.
We welcome both academic and industry teams. Individual researchers are also encouraged to participate.
Timeline
- 2026-03-15: Challenge announcement
- 2026-03-25: Phase 1 Started: Development data released
- 2026-04-10: Phase 1 Ended: Development submission portal closes
–2026-04-15–2026-04-10: Registration Deadline–2026-04-15–2026-04-23: Phase 2 Started: Evaluation data released–2026-04-25–2026-04-30: Phase 2 Ended: Evaluation submission portal closes–2026-05-10–2026-05-15: Paper Submission Deadline–2026-06-01–➤ 2026-07-15: Notification of paper acceptance–2026-06-15–2026-07-31: Camera-ready GC paper submission- 2026-11-09: APSIPA conference presentation (Bangkok, Thailand)
Contact
For questions please use GitHub Discussion or via email (radarchallenge2026 (at) gmail.com)
We strongly encourage participants to use GitHub Discussions so answers benefit all teams.
How to Get Started
- Read the rules of the challenge.
- Prepare your data pipeline and models using publicly available training datasets (respecting the training data policy).
- Download the development set (sent to participants via email) once released and evaluate your systems under the provided transformations.
- Use the baseline system and inference script as a reference for data format and scoring.
- Submit your scores and system description according to the challenge instructions and deadlines.
Task Summary
| Item | Description |
|---|---|
| Task | Binary classification (bonafide vs spoof) |
| Input | Speech waveform |
| Twist | Speech is passed through unknown media processing chains |
| Output | Spoof detection score |
| Metric | Equal Error Rate (EER) |
| Training data | Open (public datasets only) |
| Evaluation | Blind test set |
| Goal | Robust detection systems for realistic media processing |
Dataset & Protocol
- Development set
- English speech derived from LlamaPartialSpoof with additional media transformations applied. (Only the full-fake subset of LlamaPartialSpoof will be used)
- Designed to help participants develop and test robustness to various signal degradations.
- Evaluation set
- Multilingual speech data (English, Mandarin, Japanese, and Vietnamese) with unknown combinations of transformations.
- No labels are provided; participants submit detection scores per utterance.
- Training data policy
- No official training set is provided.
- Participants may use any legally accessible public datasets (open/public license) for system development, except LlamaPartialSpoof, LibriTTS dev/test splits, and any derived or overlapping data, as these are used to construct the challenge development set.
Phases
Phase 1 - Development
- 2026-03-25 RADAR2026-dev set released (English, no labels, derivative of LlamaPartialSpoof)
- 2026-04-01 (00:00 UTC) Development submission portal opens
- 2026-04-10 (23:59 UTC) Development submission portal closes
- 2026-04-13 RADAR2026-dev labels released for analysis and paper writing
The development phase is intended to help participants validate their systems and familiarize themselves with the evaluation protocol. Results from Phase 1 (Development) will not affect the final ranking. The top 5 teams in the Development Phase will receive honorary mentions and certificates.
Phase 2 - Evaluation
To be eligible for Phase 2, teams must have at least one Phase 1 submission with an EER below 37%.
–2026-04-20–2026-04-22 RADAR2026-eval set released (English, Mandarin, Japanese and Vietnamese)- 2026-04-23 (00:00 UTC) Evaluation submission portal opens
- 2026-04-30 (23:59 UTC) Evaluation submission portal closes
- 2026-06-30 Paper Submission Deadline
Results from Phase 2 (Evaluation) will determine the final ranking. Top-performing teams will be recognized at APSIPA ASC 2026 in Bangkok, Thailand.
Media Transformations
Examples of media transformation
| Original | Transformed | |
|---|---|---|
| Bonafide | ||
| Spoofed |
Each utterance in the development and evaluation sets may undergo one or more of the following while maintained their original label (bonafide/spoofed):
- Signal level operations
- Peak level adjustment
- Fade-in / fade-out
- Signal structure modifications
- Silence trimming
- Zero padding
- Environmental conditions
- Additive environmental noise
- Background music
- Room impulse response (RIR) convolution
- Media channel effects
- Audio codec compression
- Resampling
- Dynamic range compression
- Bandwidth limitation
Some transformations used in the evaluation set will not appear in the development set in order to explicitly evaluate model generalization. The number and combination of transformations applied to each utterance are randomly sampled to emulate diverse real-world media processing pipelines. Additional undisclosed transformations with similar characteristics may also be included in the evaluation set to further assess robustness to unseen conditions.
Evaluation
Primary metric: Equal Error Rate (EER) on the evaluation set.
Participants must submit one detection score per evaluation utterance (higher scores indicate higher confidence that the sample is spoofed). Leaderboard rankings are based on EER, with additional metrics possibly reported for further analysis.
EER is selected due to its simplicity and widespread use in spoofing detection research. While participants are free to interpret their results based on the leaderboard, the organizers do not endorse or take responsibility for any performance claims made based on these results.
Baseline systems
We released a baseline system to help participants get started and to illustrate the expected data pipeline and submission format.
Organizers could also submit scores and description papers for guidance; those organizer entries were excluded from the final ranking.
01. SSL AASIST Antispoofing
This baseline demonstrates the expected submission format and includes offline evaluation and analysis scripts.
Awards
This is an academic challenge without monetary prizes.
Top-performing teams will receive certificates, and outstanding submissions will be recognized at APSIPA 2026 in Bangkok, Thailand.
Organizers

Dr. Hieu-Thi Luong
Fortemedia, Singapore
Challenge Lead Organizer

Asst. Prof. Xuechen Liu
Xi'an Jiaotong-Liverpool University, China
Co-organizer

Dr. Ivan Kukanov
KLASS Engineering & Solutions, Singapore
Co-organizer

Assoc. Prof. Kong-Aik Lee
The Hong Kong Polytechnic University, Hong Kong SAR, China
Advisor
FAQs
Q: Can we use pretrained models (e.g., SSL models) that may have been trained on datasets related to LibriTTS such as MLS?
Yes. Publicly available pretrained models (Wave2Vec, WavLM, XLSR, etc.) are allowed, even if they were trained on large public speech datasets.
However, participants must not explicitly train or fine-tune models using LibriTTS dev/test splits or any derivatives of the RADAR development or evaluation data for the task of audio deepfake detection.
Q: Can I use [this dataset] for training?
We only restrict the use of LlamaPartialSpoof, LibriTTS dev/test sets, and their derivatives.
We recognize that some datasets (especially those derived from LibriSpeech/LibriTTS) may contain overlapping speakers or recordings. To avoid unnecessary restrictions, we explicitly allow the use of the following datasets for training, even if partial overlap may exist:
- LibriTTS (train split)
- LibriSpeech (train split)
- Multilingual LibriSpeech (MLS)
- ASVspoof 2019 LA
- ASVspoof 2021 LA/DF
- ASVspoof5 (train split)
- MLAAD
Participants may use these datasets with confidence for training their systems.